Sección 7 Bases de datos regionales
Muchos procesos aleatorios varían de manera continua en el espacio a escala regional. Entonces, es de interés predecir el comportamiento de una variable en referencia a su ubicación geográfica. En algunas situaciones además de la distribución en el espacio otras capas de información (covariables de sitio) pueden ser usadas para mejorar la predicción en un sitio específico. En esta parte se ilustran el manejo de datos espaciales para la predicción a escala regional de una variable a partir de múltiples capas de información y la construcción de un modelo de predicción espacial vía estrategias metodológicas alternativas: regresión múltiple vía REML, regresión múltiple vía INLA y regresión no lineal vía modelo basado en árbol.
Como ejemplo se utiliza la base de datos suelos_cba.txt. Esta es una parte del SIG de los suelos del horizonte superficial de la provincia Córdoba (Hang et al. 2015), que contiene 350 sitios caracterizados por múltiples variables edáficas que describen los primeros 15 cm de profundidad. Las variables presentes en suelos_cba.txt son: COS (Carbono Orgánico de Suelo, g/kg) arcilla (%), pH, elevación (m.s.n.m.), twi (Índice Topográfico de Humedad). El objetivo del análisis es ajustar modelos que expliquen la variabilidad espacial de COS en función de las restantes variables en la base de datos.
Para seguir la ilustración, cargar los paquetes específicos de R que albergan las funciones que se utilizarán tanto para el manejo como para la modelación.
7.1 Manejo de datos espaciales
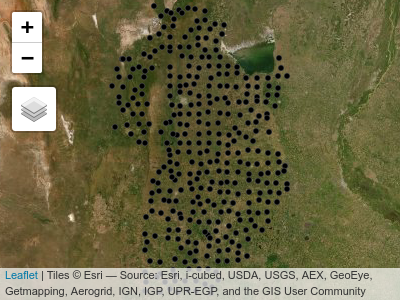
Mediante la función read.table() se lee un archivo de texto que se guarda como un objeto denominado suelos, en el cual las columnas están separadas por tabuladores y la primera fila contiene los nombres de columnas. Mediante la función head() se visualizan las primeras filas del objeto suelos donde se observa que la primera columna corresponde a una identificación, las siguientes dos son las coordenadas X e Y las cuales corresponden al sistema de proyección UTM faja 20. Las columnas siguientes contienen las variables en estudio.
suelos <- read.table("datos/suelos_cba.txt",
sep = "\t", header = TRUE)
head(suelos)
#> ID_2 X Y elevacion twi arcilla pH COS
#> 1 2 603164 6576899 100 135 30,8 6,6 26,0
#> 2 3 596537 6390518 87 133 24,0 7,4 17,3
#> [ reached 'max' / getOption("max.print") -- omitted 4 rows ]Para transformar este objeto en uno de clase espacial, se utilizará la función st_as_sf(), especificando que las coordenadas X e Y, se encuentra en las columnas “X” e “Y”, respectivamente. Todos los sistemas de coordenadas tienen asociados un código que los identifica y que a través del cual, se pueden conocer los parámetros asociados al mismo, este código se llama EPSG por su acrónimo en inglés. El código EPSG del sistema de referencia y proyección de la base de datos es 32720. El objeto suelos_sf, ahora es un objeto espacial de clase sf, donde cada observación corresponde a cada sitio de muestreo. Se muestra el sistema de referencia y proyección de las coordenadas y el tipo de geometría.
suelos_sf <- st_as_sf(suelos,
coords = c("X", "Y"),
crs = 32720)
suelos_sf
#> Simple feature collection with 350 features and 6 fields
#> geometry type: POINT
#> dimension: XY
#> bbox: xmin: 236000 ymin: 6130000 xmax: 603000 ymax: 6720000
#> epsg (SRID): 32720
#> proj4string: +proj=utm +zone=20 +south +datum=WGS84 +units=m +no_defs
#> First 3 features:
#> ID_2 elevacion twi arcilla pH COS geometry
#> 1 2 100 135 30,8 6,6 26,0 POINT (603164 6576899)
#> 2 3 87 133 24,0 7,4 17,3 POINT (596537 6390518)
#> [ reached 'max' / getOption("max.print") -- omitted 1 rows ]Para explorar los datos se usa el paquete tmap que permite realizar gráficos estáticos o dinámicos. Con la opción dinámica, se puede interactuar con el gráfico de manera análoga a un SIG. Para cada gráfico, se comienza utilizando la función tm_shape() especificando el objeto a graficar. Cada observación se grafica un punto mediante la función tm_dots(), cada nivel se agrega mediante el símbolo +.
Para agregar latitud y longitud a esta figura se realiza una reproyección. En la función tm_shape() se especifica el nuevo sistema de coordenadas con el que se desea graficar (argumento projection). Se agregar el nivel tm_grid() para visualizar una grilla que contiene las coordenadas latitud y longitud.
Cualquiera de estos gráficos se puede convertir en un gráfico dinámico mediante la función tmap_mode() especificando como argumento "view". Para continuar con gráficos estáticos se debe especificar "plot" como argumento de esta función. Mediante la función tm_basemap(), se pueden incorporar distintas capas base. Las opciones disponibles para las capas base se pueden ver mediante el comando names(leaflet::providers).
Cualquiera de estos gráficos se puede convertir en un gráfico dinámico utilizando la función tmap_mode() especificando como argumento "view". Para continuar con gráficos estáticos se debe especificar "plot" como argumento de esta función. Mediante la función tm_basemap(), se pueden incorporar distintas capas base (capas de fondo que ayudan a visualizar). Las opciones disponibles para las capas base se pueden ver mediante el comando names(leaflet::providers).
7.2 Confección de grillas de predicción
Para generar esta grilla es necesario definir una resolución espacial en el área de interés. Para este ejemplo, se utiliza un archivo vectorial, limites_cba.shp, el cual define el límite del territorio sobre el que se desea predecir.
limites_cba <- st_read("datos/limites_cba.shp",
quiet = TRUE)
limites_cba <- st_transform(limites_cba,
crs = 32720)La función st_make_grid() genera una grilla rectangular conteniendo el área del objeto limites_cba. Para definir la resolución espacial de la grilla se utiliza el argumento cellsize definiendo un tamaño de grilla en relación con la unidad de medida del sistema de coordenadas, en este caso 10000 metros, dado que está en UTM.
grilla_base <- st_make_grid(limites_cba,
cellsize = 10000)
tm_shape(grilla_base) +
tm_borders() +
tm_shape(limites_cba) +
tm_borders(col = "red")Dado que la grilla es rectangular, es necesario cortarla según los límites. Para esto se realiza una intersección entre los límites y la grilla utilizando la función st_intersection().
Los algoritmos de predicción implementados trabajan prediciendo sitios puntuales, por lo cual, a partir de la grilla, es necesario generar una grilla de puntos. Una alternativa es utilizar la función st_centroid() para obtener el centroide de cada celda.
7.3 Agregado de capas de información
Se presenta los comandos necesarios para combinar múltiples capas de información en un mismo objeto. Las variables elevación y twi son extraídas desde modelos digitales de elevación, que se encuentran en formato raster. El paquete raster de R es específico para lectura y manipulación de este tipo de archivos. Para leer un archivo de este formato, se puede utilizar la función raster() mientras que para reproyectar se utiliza la función projectRaster(). El archivo elevacion.tif contiene datos de elevación para la provincia de Córdoba. Cuando se imprime el objeto, se muestra la cantidad de pixeles por fila, columna, pixeles totales, la resolución espacial, las coordenadas extremas en latitud y longitud, el sistema de coordenadas de referencia, los valores mínimo y máximo de la variable observada.
elevacion <- raster("datos/elevacion.tif")
elevacion <-
projectRaster(elevacion,
crs = "+proj=utm +zone=20 +south
+datum=WGS84 +units=m +no_defs")
elevacion
#> class : RasterLayer
#> dimensions : 2867, 2373, 6803391 (nrow, ncol, ncell)
#> resolution : 196, 231 (x, y)
#> extent : 195205, 660313, 6099410, 6761687 (xmin, xmax, ymin, ymax)
#> crs : +proj=utm +zone=20 +south +datum=WGS84 +units=m +no_defs +ellps=WGS84 +towgs84=0,0,0
#> source : memory
#> names : elevacion
#> values : 38,6, 2746 (min, max)Para obtener en los sitios de predicción el valor de la variable del objeto raster, se utiliza la función extract() definiendo como argumento el nombre del objeto raster y el nombre del objeto vectorial que contiene los sitios. Estos valores extraídos se adicionan en una columna llamada elevacion dentro del objeto centroide_pred utilizando el símbolo $.
El archivo twi.tif contiene valores de un índice topográfico de humedad también generado a partir de datos provenientes de un modelo digital de elevación..
twi <- raster("datos/twi.tif")
twi <-
projectRaster(twi,
crs = "+proj=utm +zone=20 +south
+datum=WGS84 +units=m +no_defs")
twi
#> class : RasterLayer
#> dimensions : 1438, 1189, 1709782 (nrow, ncol, ncell)
#> resolution : 393, 462 (x, y)
#> extent : 194023, 661300, 6098486, 6762842 (xmin, xmax, ymin, ymax)
#> crs : +proj=utm +zone=20 +south +datum=WGS84 +units=m +no_defs +ellps=WGS84 +towgs84=0,0,0
#> source : memory
#> names : twi
#> values : 54, 138 (min, max)Utilizando la función extract() se extrae los valores de TWI para cada sitio de la grilla de predicción.
Se adiciona a la grilla variables procedentes de otras fuentes (SIG de muestreo de suelo). Estos datos se encuentran en los archivos raster llamados arcilla.tif y pH.tif, respectivamente. Estos raster tienen la misma resolución espacial y extensión, por lo que es posible superponerlos en un mismo objeto mediante la función stack().
arcilla <- raster("datos/arcilla.tif")
pH <- raster("datos/pH.tif")
edaf <- stack(pH, arcilla)
projection(edaf) <-
"+proj=utm +zone=20 +south
+datum=WGS84 +units=m +no_defs"
tm_shape(edaf) +
tm_raster()
#> Tip: rasters can be shown as layers instead of facets by setting tm_facets(as.layers = TRUE).Se seleccionan los valores de los sitios utilizando la función extract(). Como los valores extraídos mediante la funcion desde un stack de rasters genera un objeto de tipo data.frame con tantas columnas como capas contenga ese raster, se adicionan al objeto centroide_pred mediante la función cbind(), la cual une columnas de igual número de filas. Ahora el objeto cetroide_pred contiene todos los sitios de predicción con las variables auxiliares adicionadas.
edaf_pred <- raster::extract(edaf,
centroide_pred)
centroide_pred <- cbind(centroide_pred,
edaf_pred)
centroide_pred
#> Simple feature collection with 1668 features and 8 fields
#> geometry type: POINT
#> dimension: XY
#> bbox: xmin: 239000 ymin: 6130000 xmax: 615000 ymax: 6730000
#> epsg (SRID): 32720
#> proj4string: +proj=utm +zone=20 +south +datum=WGS84 +units=m +no_defs
#> First 3 features:
#> UNION JURISDICCI CAPITAL FUENTE elevacion twi pH arcilla
#> 1 -2,15e+09 CORDOBA CORDOBA IGN 275 118 6,39 8,21
#> geometry
#> 1 POINT (310499 6129968)
#> [ reached 'max' / getOption("max.print") -- omitted 2 rows ]Para identificar la variación de la variable de interés en un plano, se puede usar una escala de colores. La elección de la escala cambia según los colores y los puntos de corte (valores de la variable de interés en los cuales cambia el color). Para definirla algunas opciones automáticamente identifican los valores para categorizar y asignar un color. Por defecto, tmap categoriza los valores en intervalos fijos. Utilizando el argumento style, se puede modificar el método a utilizar. Las opciones style = "order" y style = "cont" permiten representar variables numéricas en un gradiente de color. La opción “order” realiza una escala en función del ranking de los valores, permitiendo una mejor visualización de variables asimétricas. Para la visualización de más de un mapa generado con tmap en un mismo gráfico, se puede utilizar la función tmap_arrange(), utilizando como argumento los mapas que se quieren visualizar. El argumento sync = TRUE permite la visualización interactiva con la navegación (zoom y movimiento) sincronizada en ambos mapas.
elevTm <- tm_shape(centroide_pred) +
tm_dots("elevacion", style = "order")
twiTm <- tm_shape(centroide_pred) +
tm_dots("twi", style = "cont")
pHTM <- tm_shape(centroide_pred) +
tm_dots("pH", style = "cont")
arcillaTm <- tm_shape(centroide_pred) +
tm_dots("arcilla", style = "cont")
tmap_arrange(elevTm, twiTm, pHTM, arcillaTm,
ncol = 2)Referencias
Hang, Susana, Gustavo Negro, Alejandro Becerra, and Ariel Edgar Rampoldi. 2015. Suelos de Córdoba: Variabilidad de las propiedades del horizonte superficial. Córdoba: Jorge Omar Editorial.